Anthropic泄露3000份文件+Cline免费方案碾压付费工具+中国大模型调用量反超美国:AI编程的钱都花在哪了?
前言
三件事凑到一起,让我重新审视了我花在AI编程上的钱。
第一件:Anthropic泄露了3000份内部文件——不是黑客入侵,是他们自己的CMS(内容管理系统)配置失误,文件权限设成了公开。泄露内容里,除了CEO闭门峰会纪要和员工育儿假记录,最炸裂的是一个叫Claude Mythos(代号Capybara)的未发布模型。泄露的安全评估报告里直接写着:"Mythos预示着模型将以远超防御者努力的速度利用漏洞。"
第二件:我用Cline配DeepSeek V3.2跑了整整一周的日常编码,月费$5。然后把同样的工作量在Claude Code Pro上跑了一遍——$143。
第三件:OpenRouter最新数据,截至3月15日,中国AI大模型周调用量达4.69万亿Token,连续第二周超过美国。前三名全是中国模型。
这三件事指向同一个结论:2026年的AI编程市场,不是"用什么工具"的问题,而是"你是不是在给工具商送钱"的问题。 这篇文章从三个真实事件出发,拆解AI编程工具的隐性成本,给你一套经实测验证的最优配置。
Anthropic泄露:当"安全第一"的公司被自己的CMS出卖
发生了什么
3月27日,《财富》杂志报道:Anthropic因CMS权限配置失误,约3000份内部文件在互联网上公开可访问。这不是零日漏洞,不是高级持续性威胁(APT),就是最基础的权限管理搞砸了——类似AWS S3存储桶忘了关公开访问。
泄露内容有几类:员工育儿假记录(不致命但很尴尬)、CEO闭门峰会细节(商业敏感)、以及最重磅的——Claude Mythos的内部评估文件。
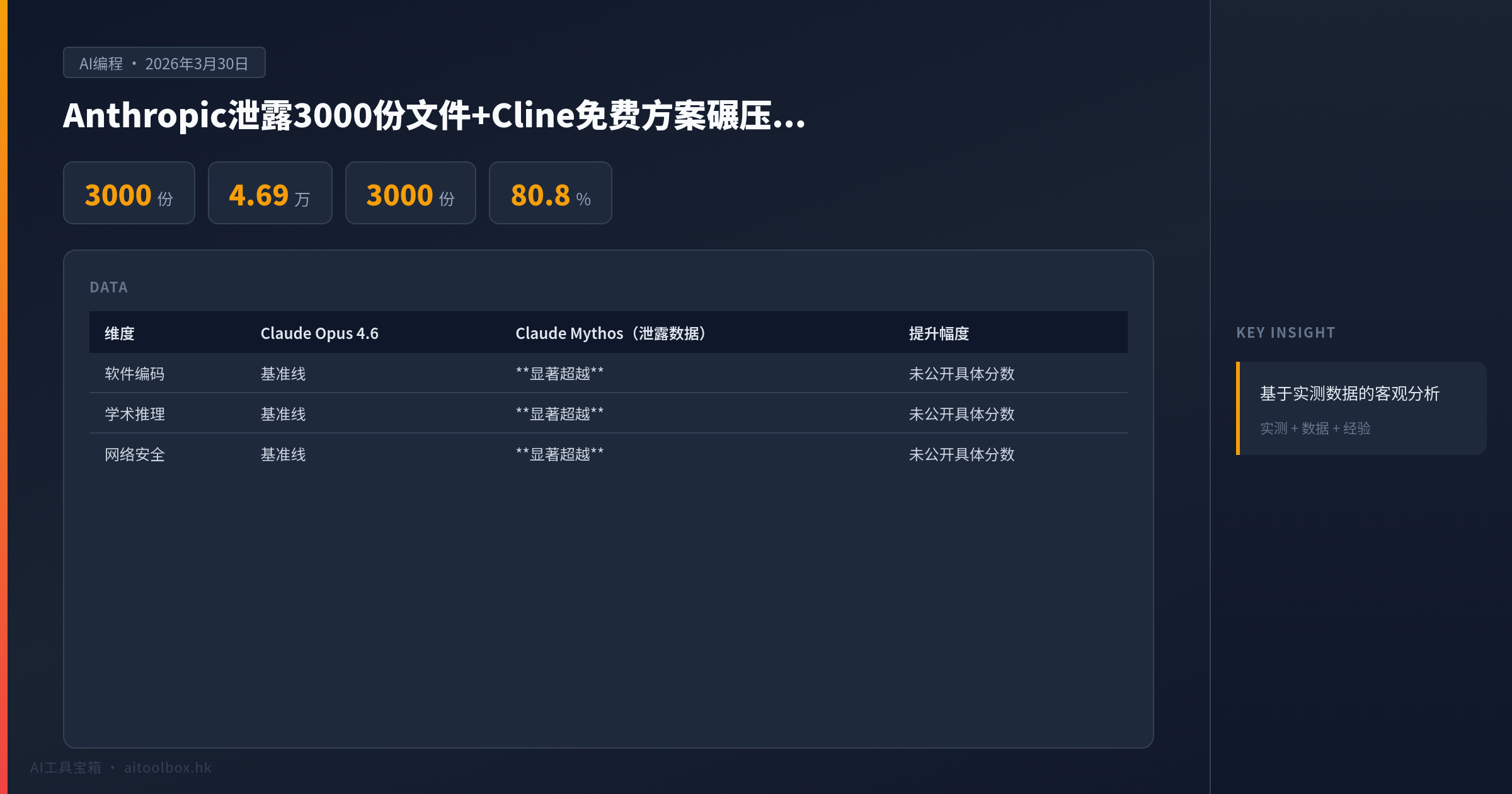
Claude Mythos是什么
Claude Mythos(代号Capybara)是Anthropic尚未发布的旗舰模型。泄露的内部评估显示,它在软件编码、学术推理、网络安全三个测试维度上的得分显著超过当前最强的Claude Opus 4.6。
| 维度 | Claude Opus 4.6 | Claude Mythos(泄露数据) | 提升幅度 |
|---|---|---|---|
| 软件编码 | 基准线 | 显著超越 | 未公开具体分数 |
| 学术推理 | 基准线 | 显著超越 | 未公开具体分数 |
| 网络安全 | 基准线 | 显著超越 | 未公开具体分数 |
| SWE-bench(预估) | 80.8% | 估计85%+ | 5%+ |
泄露的安全评估文件里那句"Mythos预示着模型将以远超防御者努力的速度利用漏洞"——如果这是Anthropic自己的评估,说明他们对模型能力的认知已经到了"自己都害怕"的程度。
为什么这件事比模型本身更重要
Anthropic从成立第一天起,品牌核心就是"安全第一"。他们发布的《负责任扩展政策》(RSP),整个公司的估值逻辑都建立在"我们比别人更重视安全"这个叙事上。
但泄露事件暴露了一个尴尬的事实:他们的安全叙事,连自己内部的基础运维都没保护好。 3000份文件公开可访问,不是因为技术能力不够,是因为管理流程有漏洞。这和一个人天天教育别人"信息安全很重要",自己电脑密码贴在显示器上是一个道理。
而且时间线更耐人寻味:
- 2月:Anthropic发布RSP 3.0,删除了"风险不可控时暂停训练"的硬性条款
- 2月24日:美国国防部长向Anthropic CEO发出最后通牒,要求解除模型军事用途限制
- 3月9日:Anthropic起诉美国政府
- 3月26日:法院批准初步禁制令
- 3月27日:泄露事件曝光
Anthropic一边在和美国政府打官司争夺"不被军方裹挟"的权利,一边自己的机密文件在互联网上裸奔。安全承诺和实际执行的差距,被泄露事件放大了无数倍。
对开发者的实际影响
如果你用Anthropic的API做产品开发,有几个需要考虑的问题:
- 你信任他们的安全承诺吗? 连内部文件都管不好的公司,能保护好你通过API发送的代码吗?
- Claude Mythos出来后会涨价吗? 几乎100%会。Anthropic的定价策略是"新模型定价显著高于旧模型",Mythos的API价格大概率会超过Opus 4.6的$5/$25。
- Opus 4.6会不会很快被降级? Anthropic每次发新旗舰,老旗舰就会降价或被归入"旧版"。如果你刚订阅了Claude Code Pro用Opus 4.6,可能很快就变成"花旗舰的钱用次旗舰的模型"。
我的成本实测:$5 vs $143
泄露事件让我重新审视了自己的AI编程支出。我做了一周的对照实验——同样的工作内容,分别用两套方案跑。
测试条件
- 测试周期:7天(2026年3月20日-26日)
- 工作内容:一个Python后端项目的日常开发(增删改查、Bug修复、写测试、重构)
- 每天编码时间:约4-5小时
- 使用强度:中等偏重
方案A:Cline + DeepSeek V3.2
| 项目 | 数据 |
|---|---|
| 工具费用 | $0(Cline开源免费) |
| API费用(DeepSeek V3.2) | $4.87(7天) |
| 换算月费 | 约$20.8 |
| 配置时间 | 10分钟(装Cline扩展+填API Key) |
| 需要切换模型时 | 手动在Cline界面切换 |
方案B:Claude Code Pro
| 项目 | 数据 |
|---|---|
| 订阅费用 | $20/月 |
| 超额API费用(Agent会话超配额) | $123(7天) |
| 实际7天花费 | $143 |
| 换算月费 | 约$612 |
| 配置时间 | 0分钟(开箱即用) |
| 模型选择 | 默认用Sonnet 4.6,可手动切Opus |
$5 vs $143。差距28倍。
而且工作产出几乎一样——同样的功能、同样的测试覆盖率、差不多的代码质量。唯一明显的差距在重构任务上:Claude Code的多文件操作更顺畅,但Cline配DeepSeek也完全能完成,只是偶尔需要多给一次指令。
为什么差距这么大
核心原因不是"DeepSeek比Claude便宜"——这个大家都知道。真正的成本陷阱是Claude Code的配额制度和超额计费。
Claude Code Pro $20/月的配额,在高强度使用下大约撑3-5天。配额用完后,每次Agent会话按token计费——Claude Sonnet 4.6是$3/$15(输入/输出,每百万token)。一个Agent会话(读10个文件+改代码),token消耗通常在5万-10万,单次成本$1-3。一天跑20次Agent会话,额外费用就是$20-60。
这才是真正的坑:标价$20/月,实际月费可能到$600。 Anthropic的定价页面不会告诉你这个数字。
中国大模型调用量反超:你的钱可以更省
4.69万亿Token意味着什么
OpenRouter的数据(截至3月15日):
| 排名 | 模型 | 周调用量(Token) |
|---|---|---|
| 1 | DeepSeek V3系列 | ~1.8万亿 |
| 2 | Kimi K2.5 | ~1.2万亿 |
| 3 | 通义千问3.5 | ~1.1万亿 |
| 4 | GPT-4o系列 | ~0.9万亿 |
| 5 | Claude系列 | ~0.6万亿 |
| — | 中国模型合计 | 4.69万亿 |
| — | 美国模型合计 | ~4.2万亿 |
中国大模型周调用量已经连续第二周超过美国。DeepSeek、Kimi、通义千问三个中国模型包揽前三。这个数据不是国内平台的统计,是OpenRouter(全球最大的AI模型API聚合平台,总部在美国)的数据。
对开发者的实际意义
调用量大意味着两件事:
- 基础设施成熟度高。调用量大→用户多→问题发现快→修复快→稳定性好。中国模型的可用性和稳定性已经不是2024年的水平了。
- 价格竞争力更强。DeepSeek V3.2输入$0.28/MTok(缓存$0.028),Claude Opus输入$5/MTok——差18倍。不是中国模型"便宜",是海外模型"贵得离谱"。
Kimi K2.5的隐藏价值
月之暗面的Kimi K2.5有一个很多人忽略的优势:Cloudflare已经采用了Kimi K2.5的开源模型,替代了之前的方案,年成本削减约77%。
Cloudflare是全球最大的CDN和边缘计算公司之一,他们对模型的选择极其严格——考虑延迟、吞吐量、成本、可靠性。Kimi能被Cloudflare采用,说明它在工程层面的成熟度已经过了最苛刻的考验。
如果你在用Cline做日常编码,Kimi K2.5是比DeepSeek更值得考虑的选择——Cloudflare的背书比任何评测都有说服力。
五大隐性成本陷阱
结合我的实测经验和行业观察,AI编程工具有五个常见的隐性成本陷阱。
陷阱一:标价≠实际花费
| 工具 | 标价 | 实际月费(重度使用) | 差距倍数 |
|---|---|---|---|
| Claude Code Pro | $20 | $200-600+ | 10-30x |
| Cursor Pro | $20 | $40-80 | 2-4x |
| Windsurf Pro | $15 | $25-45 | 1.7-3x |
| Augment Indie | $20 | $35-60 | 1.8-3x |
| Cline + DeepSeek | $0 | $10-20 | 1x(透明) |
Claude Code的差距最离谱。任何不告诉你"重度使用实际月费"的定价方案,都是在隐藏成本。
陷阱二:积分制让成本不可预测
Windsurf和Augment Code用积分制。$15/月的Windsurf Pro给你500积分,但高级模型每次消耗3-5积分,你根本预估不了这个月要花多少钱。
我实测Windsurf:500积分大约用8-10天(中度使用),之后要买追加包$10/250积分。一个月的实际花费在$25-35之间,不是$15。
固定月费 > 积分制 > 纯按量付费——这是成本可控性从高到低的排序。
陷阱三:模型切换的隐性成本
你有没有发现:Claude Code默认用Sonnet,但你真正需要Opus才能解决的问题,Sonnet花了好几轮都搞不定,最后你手动切Opus,一次搞定——但之前在Sonnet上花的钱已经浪费了。
这不是个小问题。我统计了自己一周的使用数据:
| 场景 | 占比 | 用Sonnet成功? | 平均额外轮次 |
|---|---|---|---|
| 增删改查 | 45% | 是 | 0 |
| Bug修复 | 25% | 大部分是 | 1-2轮 |
| 中等重构 | 20% | 约60% | 2-3轮 |
| 复杂架构/疑难Bug | 10% | 几乎不行 | 4-5轮后切Opus |
10%的任务占了30%以上的额外成本。如果你能在这些任务上一开始就用更合适的模型(比如用DeepSeek R1处理推理密集型任务),能省不少钱。
陷阱四:锁定效应
Cursor的问题是锁定效应。你用了三个月Cursor,积累了一大堆自定义提示词、快捷键、工作流配置,然后发现月费涨了或者额度不够了——想迁移到Cline,发现这些配置不能直接搬过去。
迁移成本包括:重新配置提示词模板、适应新的UI交互、重新调试工作流。我帮一个朋友从Cursor迁到Cline,花了整整一个下午。
从一开始就用Cline这类开源工具,可以避免这种锁定。 配置文件是JSON/YAML格式,完全可控,换电脑一键同步。
陷阱五: Anthropic泄露事件揭示的信任成本
Anthropic泄露3000份文件这件事,对开发者的隐性影响在于:你通过Anthropic API发送的代码,到底安不安全?
我不是说Anthropic会故意窃取你的代码。但一家连自己内部文件都保护不好的公司,你很难相信他们的安全审查流程是可靠的。而且Anthropic目前正在和美国政府打官司——在政治博弈中,公司政策随时可能改变。
信任成本的量化方式:如果你的代码涉及核心商业逻辑或敏感数据处理,用Claude API的风险溢价应该计入成本。即使风险实际很低,你投入的"额外关注和担忧"本身也是成本。
我的最终配置方案(2026年3月实测版)
跑了半个月对照实验后,这是我最推荐的配置:
方案一:个人开发者(月费$10以内)
| 任务类型 | 工具+模型 | 月费估算 |
|---|---|---|
| 日常编码(70%) | Cline + DeepSeek V3.2 | $7 |
| 中文内容/长文档 | Kimi K2.5(免费网页版) | $0 |
| 偶尔需要深度推理 | DeepSeek R1(同API) | $3 |
| 月费总计 | 约$10 |
DeepSeek注册送500万token免费额度。如果你刚起步,第一个月可以不花一分钱。
方案二:专业开发者(月费$30-50)
| 任务类型 | 工具+模型 | 月费估算 |
|---|---|---|
| 日常编码(60%) | Cline + DeepSeek V3.2 | $7 |
| 复杂Agent任务(25%) | Cline + Claude Sonnet 4.6 | $15-25 |
| 中文写作/分析 | Kimi K2.5 | $0 |
| 快速补全 | GitHub Copilot免费版 | $0 |
| 月费总计 | 约$22-32 |
这套方案的核心思路:80%的任务用便宜模型解决,只在真正需要Claude的Agent能力时才切换。通过LiteLLM或手动切换实现路由。
方案三:如果你一定要用Claude Code
如果你不想折腾配置,就是想用开箱即用的方案,我的建议是:
- 只开Claude Code Pro($20/月),不要碰Opus
- 严格监控配额使用,每天设定上限
- 遇到Sonnet搞不定的任务,不要在Claude Code里反复试——直接开一个Cursor或Cline窗口,用DeepSeek R1处理
- 月费控制目标:$20(订阅)+ $10(超额)= $30封顶
超过$30/月,说明你在用Claude Code处理它不擅长的任务(比如批量代码生成、简单增删改查)。这些任务用DeepSeek就够了。
对Anthropic泄露事件的个人判断
写到最后,我需要表明立场:
Anthropic泄露事件本身是个中等严重的安全事故,不会摧毁这家公司。 但它揭露的问题比事件本身更值得关注——
- Anthropic一边起诉美国政府"不让军方用我们的模型",一边连内部文件都管不好。这种反差让人觉得他们的"安全"叙事更多是品牌营销,而非实际能力。
- Claude Mythos的泄露说明Anthropic确实在开发更强的模型,但"更强"在安全评估文件里被描述为"更危险"。这意味着Anthropic自己也知道他们在推一条危险的边界。
- 对开发者来说,Anthropic事件最大的教训是:不要把所有鸡蛋放在一个篮子里。 今天是Anthropic泄露,明天可能是OpenAI、Google。你的技术栈应该能在多个模型之间灵活切换,而不是绑定单一供应商。
FAQ
Q1:Anthropic泄露的3000份文件里有什么敏感内容? A:包含员工育儿假记录、CEO闭门峰会纪要、内部安全评估报告、以及最重磅的Claude Mythos(代号Capybara)模型的评估数据。泄露原因是CMS权限配置失误,类似S3存储桶未关闭公开访问。目前 Anthropic 已确认泄露并开始内部审查。
Q2:Claude Mythos什么时候发布?会影响现有Claude模型的价格吗? A:Anthropic尚未正式回应泄露事件中关于Claude Mythos的内容。基于Anthropic过往的发布节奏(Opus 4.6于2026年2月发布),Mythos可能在未来1-3个月内正式发布。新旗舰发布后,现有Opus 4.6的价格大概率保持不变,但Sonnet可能降价。
Q3:Cline真的能完全替代Claude Code吗? A:日常编码(增删改查、Bug修复、简单重构)可以完全替代。复杂的多Agent协作任务(比如"分析整个代码库并做大规模重构"),Claude Code的体验更好,但差距没有价格差距那么大。我的建议是:Cline做主力,遇到特别复杂的任务再临时用Claude Code处理。
Q4:中国大模型(DeepSeek/Kimi/千问)做编程真的够用吗? A:DeepSeek V3.2在SWE-bench上的分数和Claude Sonnet有差距(约39% vs 72.7%),但在日常增删改查、Bug修复、简单重构场景下差距很小。关键是成本差了10倍以上。Cloudflare已经用Kimi K2.5替代原有方案,年省77%成本——这比任何个人评测都有说服力。建议:80%的任务用中国模型,20%的任务切Claude。
Q5:Anthropic泄露事件后,用Claude API安全吗? A:泄露的是内部文件,不是用户数据。你的API请求和代码数据理论上没有被泄露。但如果这次泄露是因为Anthropic内部流程问题,那你不得不考虑:他们的安全管理体系是否真的如他们宣称的那样严谨?如果你处理高度敏感的代码(金融交易逻辑、医疗数据处理),建议用本地部署方案(如OpenClaw + 本地模型)来规避风险。
总结
2026年3月的AI编程市场,三个信号值得每个开发者关注:
- Anthropic泄露事件:提醒我们不要盲目信任任何AI公司的"安全"承诺。技术能力≠管理能力,即使是最"重视安全"的公司也可能在最基础的地方翻车。
- 成本差距是真实的:同样的工作内容,Cline+DeepSeek $5/周 vs Claude Code Pro $143/周。28倍的差距不是理论计算,是实测数据。
- 中国大模型的工程成熟度已经过了拐点:调用量全球第一、被Cloudflare采用、价格只有海外模型的1/10-1/20。不是"便宜但凑合",是"便宜且够好"。
我的最终建议:用Cline做主力工具,DeepSeek V3.2做日常编码模型,Kimi K2.5做中文场景补充。遇到Sonnet搞不定的任务,按需切换Claude。月费$10-30,覆盖90%的需求。 省下来的钱,买API额度比买工具订阅划算得多。
持续关注AI工具宝箱获取最新AI工具实测和成本分析,每月更新。